
Paper 研习社新功能上线啦!
大家除了浏览或者参与论文推荐,还可以一键打包下载论文合集,针对长期更新的论文合集,你能通过系统消息第一时间收到更新的通知,让你的科研的道路上,绝不慢人一步!



点击链接迅速跳转论文集下载界面:
https://paper.yanxishe.com/library
「本周论文推荐精选」是 Paper 研习社推出的全新栏目,展现社友们在研习论文的过程中,推荐自己所阅读到的优秀论文,帮助大家一起学习、讨论每个领域最新、最精彩的学术论文。
①
#计算机视觉# #深度学习#
《【北大/诺亚/鹏城/悉大】AdderNet:能否让深度学习摆脱乘法运算?》
推荐理由:
这是一篇来自华为诺亚方舟实验室的论文,于2020年1月1日上线arXiv。本文探究的目标为更高效的深度卷积神经网络。(似乎称作“模型压缩”不太妥当?因为参数量、运算量、参数精度都未减少,但是将乘法替代为加法为推断效率提供了极大的增长空间)
为了提升深度神经网络的运行效率、减少不必要的运算,常见的方法有网络剪枝、知识蒸馏等等。本文则另辟蹊径,尝试让卷积神经网络摆脱乘法而只使用高效的加法运算。
卷积神经网络的实现中,卷积运算是通过卷积核与输入特征的互相关(cross-correlation)运算实现的,而这涉及大量浮点数的乘法运算——要知道,计算机完成一次32位浮点乘法运算往往是加法运算的几倍!如果能将互相关运算替代为效果相近而仅涉及加法的运算,岂不是可以极大地提升CNN的运行效率?

32位浮点运算的相对能耗
那么问题来了:互相关的本质是什么呢?是衡量卷积核与输入特征的相似度。这里,作者大胆地使用L1距离的相反数代替互相关运算,作为衡量相似度的另一种途径。
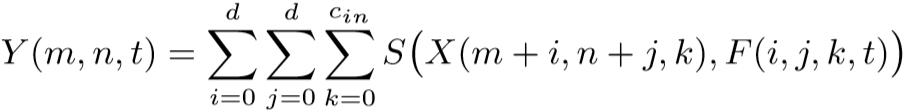
使用互相关实现的卷积运算,X为输入特征,F为卷积核,S()为乘法,Y为层的输出
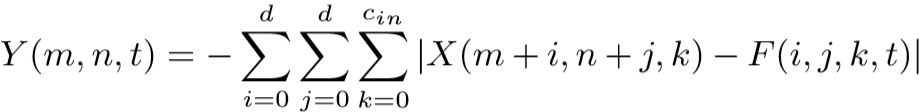
将S()换为L1距离
那么问题又来了:模型如何通过反向传播优化?如果对L1距离求导,那么结果只能是0和±1(认为L1距离等于0时导数为0),相当于对X(m+i,n+j,k)-F(i,j,k,t)求的符号函数——这并不能很好地使得模型向最优的方向优化。因此,作者在这里使用了X与F的差作为每层“卷积”核的梯度进行反传:
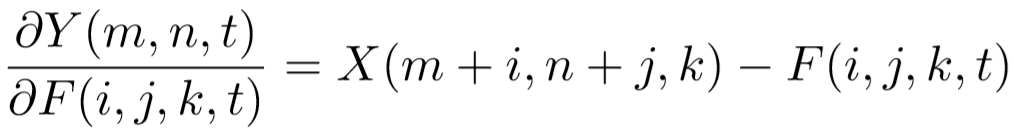
同样,X也需要梯度来回传至上层,而且与F的梯度不同的是:这个梯度还会影响到上面的所有的层(存在梯度爆炸的可能性),更需要精心的设计。因此,在这里作者使用了HardTanh(即将y=x用±1截断,防止梯度过大)使得梯度值(F-X)处于±1范围之内。
除此之外,本文还提出了针对加法网络的自适应性学习率调整策略。将所有卷积层替换为加法层的AdderNet-ResNet50在ImageNet上达到了74.9%的Top-1准确率和91.7%的Top-5准确率(使用乘法运算实现卷积的ResNet50准确率才不过76.2%和92.9%),在性能损失极少的条件下大大地减少了运算时间。
注:尽管卷积层完全未使用乘法,AdderNet-ResNet50仍然在层间采用了涉及乘法运算的批归一化(Batch Normalization)(毕竟L1距离的相反数一定是非正的)。但是与卷积层的乘法运算相比,批归一化的乘法运算量完全不在一个数量级上,因此可以被忽略不计。
论文链接:
https://paper.yanxishe.com/review/7775
推荐人:林肯二百一十三(西安交通大学,软件工程)
②
#自然语言处理# #机器学习#
《关于大熊猫的论文:用声音预测交配成功与否》
推荐理由:
用到GRU和注意力的论文有很多,但用卷积+双向GRU+注意力研究大熊猫声音的,而且就来自四川濒危野生动物保护国家重点实验室 - 成都大熊猫繁育研究基地的,这篇论文可是独一篇。
这篇论文研究的课题让我们增进了对大熊猫的认识。一方面,大熊猫一般都是比较安静的动物,不怎么发出声音,但在繁殖季时发声会明显多一些,这说明声音对求偶和交配有一定作用,此前的生物学研究也证明了存在相关性。另一方面,交配之后熊猫是否成功受孕很难确定,不仅因为熊猫胎儿非常小,只能通过其他因素观察,还因为人工养殖条件下的熊猫就出现过“为了享受更好待遇而假装怀孕”的事情。所以这篇论文的目标是通过记录下的熊猫声音预测是否成功受孕,整个工作流程包括分割、音量和长度标准化、特征提取、用含有卷积+GRU+注意力的深度神经网络预测是否成功受孕。作者们在过去 9 年中采集的声音数据集上做了实验,得到了有潜力的结果。准确的预测能给大熊猫的繁育带来帮助。
论文链接:
https://paper.yanxishe.com/review/7884
推荐人:杨 晓凡(雷锋网 主笔)
③
#计算语言学# #情感识别#
《用于语音情感识别的学习可迁移特征》
推荐理由:
语音情感识别是高级人机交互中获取情感智能的关键步骤之一,识别人类语音中的情感需要建模具有鲁棒性和区分性的特征。这篇论文提出了一种深度模型,该模型利用卷积网络来提取领域共享特征,并使用一个LSTM模型以及领域特定特征来对情感进行分类。考虑到现有语音情感数据十分稀缺,文章使用来源于多个源领域的可迁移特征来进行模型迁移。在针对不同语音情感领域的综合跨语料库实验表明,可迁移特征能够将语音情感识别任务的性能提升4.3%至18.4%。
论文链接:
https://paper.yanxishe.com/review/7938
推荐人:温蒂•斯普林
④
#深度学习# #强化学习#
《工作预测:从深度神经网络模型到应用》
推荐理由:
这篇论文考虑的是基于简历信息判断工作胜任程度的问题。
如何根据简历上的信息,例如学历、技能描述等,来判断一份工作是否适合求职者是一个困难的自然语言处理问题。反过来,公司挑选最适合这份工作的人才也是困难的。这篇论文尝试利用不同的深度神经网络模型来学习预测职业,这些模型包括TextCNN,Bi-GRU-LSTM-CNN,以及Bi-GRU-CNN,并用到了基于互联网职业数据集训练的多种预训练词嵌入。这篇论文还提出一种简单但高效的集成模型以包含不同的深度神经网络模型。实验结果表明,所提方法获得了最高为72.71%的F1值。
这篇论文试图利用自然语言处理的技术来帮助互联网上的求职者找到更适合自己的职业发展方向。
论文链接:
https://paper.yanxishe.com/review/7937
推荐人:琴•福克纳(清华大学 | 信息与通信工程 Paper研习社特约作者)
⑤
#计算语言学#
《将事实提取和验证与神经语义匹配网络相结合》
推荐理由:
对错误信息的日益关注刺激了对自动事实检查的研究。最近发布的FEVER数据集引入了基准事实验证任务,其中要求系统使用来自Wikipedia文档的证据语句来验证索赔。
在本文中,作者提出了一个由三个同类神经语义匹配模型组成的连接系统,该模型共同进行文档检索,句子选择和要求验证,以进行事实提取和验证。对于证据检索(文档检索和句子选择),不像传统的向量空间IR模型(在某些预先设计的术语向量空间中对查询和来源进行匹配),我们假设没有中间语言,作者开发了神经模型以从原始文本输入执行深度语义匹配术语表示,无权访问结构化的外部知识库。作者还显示了Pageview频率还可以帮助提高证据检索结果的性能,以后可以使用其神经语义匹配网络进行匹配。为了进行声明验证,与以前仅将上游检索到的证据和声明提供给自然语言推理(NLI)模型的方法不同,作者通过为NLI模型提供内部语义相关性评分(因此将其与证据检索模块集成)来进一步增强NLI模型和本体的WordNet功能。
论文在FEVER数据集上的实验表明:(1)作者的神经语义匹配方法在所有证据检索指标上都有显着优势,胜过流行的TF-IDF和编码器模型;(2)附加的相关性评分和WordNet功能通过更好的语义改进了NLI模型(3)通过将所有三个子任务形式化为相似的语义匹配问题并在所有三个阶段进行改进,完整的模型能够在FEVER测试集上获得最新的结果。
论文链接:
https://paper.yanxishe.com/review/7868
推荐人:hm(香港城市大学 计算机科学)
✎✎✎
除了上述的的五篇精选论文推荐,我们还为你精心准备了可以一键下载的论文集:
2019十大经典学术论文盘点
下载地址:https://paper.yanxishe.com/packages/454
NIPS, ACL, EMNLP 2019 最佳论文集 附Review
下载地址:https://paper.yanxishe.com/packages/453
年度精选 深度学习中的不确定性量化
下载地址:https://paper.yanxishe.com/packages/455
ICCV 2019 | 最新公开的51篇 Oral Paper 合集
下载地址:https://www.yanxishe.com/resourceDetail/1010
EMNLP 2019 | 10篇论文实现代码合集及下载
下载地址:https://www.yanxishe.com/resourceDetail/1013
NeurIPS 2019 GNN 论文合集
下载地址:https://www.yanxishe.com/resourceDetail/1006
AAAI (1996-2019)历年最佳论文合集
下载地址:https://www.yanxishe.com/resourceDetail/991
快来下载试试吧!
想要阅读更多精彩论文?
点击阅读原文跳转 paper.yanxishe.com



